
Data mining and sentiment analysis
The data mining component retrieves a set of data on CRFS elements and analyzes them using natural language processing and sentiment analysis
Introduction
This S2CP component is based on the use of various python libraries designed for sentiment analysis in text reviews, as well as data extraction using advanced web scraping techniques from recognized platforms such as Google Reviews, TripAdvisor and Yelp.
To guarantee accuracy in the evaluation of feelings and emotions, all texts must be in English, the language in which the analysis is carried out using Natural Language Processing (NLP). These tools allow us to automatically determine whether a text conveys a positive, negative or neutral sentiment within the specific context of restaurant reviews in this context.
In addition, the application identifies and analyzes the underlying emotions in the text, discerning emotional states such as happiness (“happy”), sadness (“sad”) or anger (“angry”).
The application’s web interface offers users the ability to directly enter raw text for analysis or enter the URL of a specific restaurant, from which relevant reviews will be automatically extracted.
An additional component of the application deals with project management, where the results obtained from emotional analysis are stored and organized. This functionality allows users to compare and contrast the predominant emotions between different projects, and also provides a global analysis of the emotions captured in all projects.
The fundamental purpose of this tool is to provide users with a detailed understanding of the sentiment and emotion expressed in food-related contexts, such as restaurant reviews. With this information, users can make informed decisions about where to eat or what places to visit, based on an objective and analytical evaluation of the opinions of other users.
Architectural design
The architecture of this application has been designed to integrate the essential functionalities of both the backend and the frontend (see Figure 8). On the backend, an SQLite database hosted on a cloud-based environment is implemented, ensuring persistence and reliable data management. The backend components also include a FastAPI server that makes it easy to create a RESTful API , using technologies such as Playwright, BeautifulSoup, and transformers for browser automation and web data analysis. On the other hand, the frontend is made up of a static web server that uses HTML, CSS and JavaScript to provide an interactive and visually appealing user interface. This architecture allows customers to interact intuitively with the application, accessing functionalities such as sentiment analysis and project management in an efficient and accessible way.

Functionalities
This S2CP component offers a variety of features designed to meet the needs raised in the project. One of the main functionalities is the ability to create new projects. This feature allows users to organize and manage different sets of review analysis. When creating a project, a dedicated space is assigned where all the reviews associated with that project are stored and processed, facilitating an orderly and segmented analysis. In addition, the UI allows users to easily switch between projects. This functionality is crucial for comparing and contrasting results from different data sets. The ability to switch between projects helps users identify patterns and trends in review data, thus improving the quality of decisions based on these analyses.
Another key feature of the app is the option to analyze raw text directly entered by the user. This functionality allows users to perform analysis of individual text fragments. Raw text analysis is especially useful for personalized evaluations, where an understanding of the sentiments and emotions expressed in a particular text is needed. In addition, the app allows entering the URL of a specific restaurant to automatically extract and analyze all the reviews available on that page. This feature provides an automated way to obtain and analyze large volumes of review data, saving users time and effort.
The following figure shows the two review mining options. Option (a) “Analyze raw text”, which allows you to analyze a single review entered by the user, Option (b), to analyze the reviews of a specific restaurant.
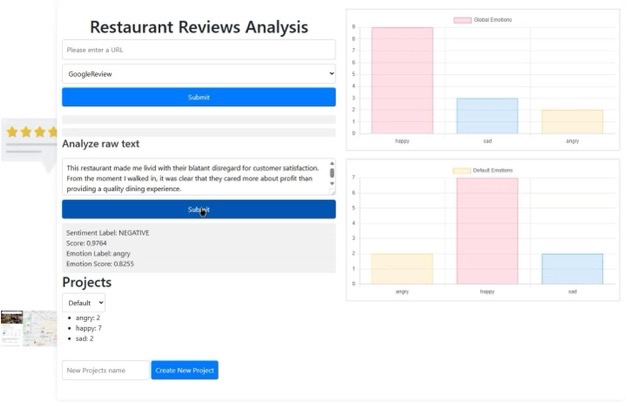
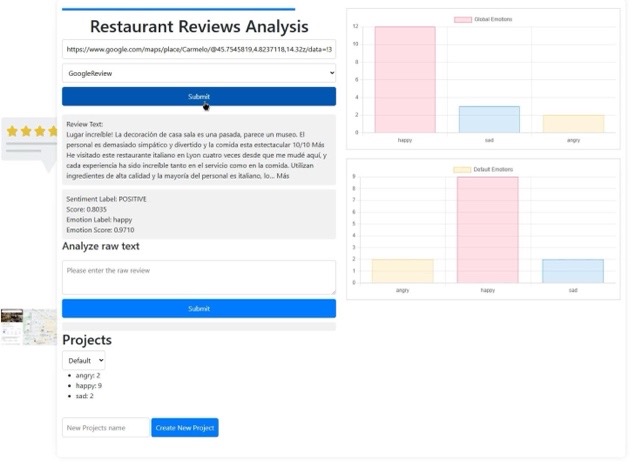
Experiments
The data mining component was developed between the second and third phases of the Combined Development Methodology (see Section 2) and was presented at the workshop “Data mining for living labs and community platform”, part of the General Assembly in Marseille, on 20th June 2024. At this workshop, the attendees, representatives of the Cities2030 CRFS labs, tested the operation of the application by suggesting places they knew, such as restaurants and review sites, and played at anticipating the result of the application after carrying out the sentiment analysis.

Conclusions
In conclusion, a complete and functional system for sentiment analysis of reviews of food-related places has been developed. Using state-of-the-art techniques in natural language processing (NLP) and web scraping, the system allows users to gain a detailed understanding of the emotions expressed in customer reviews. This ability to discern positive, negative and neutral sentiments, as well as specific emotions such as happiness, sadness or anger, provides a solid basis for decision making in the gastronomic context.
Despite its effectiveness, the identified limitations provide a clear roadmap for future improvements, including continuous adaptation to changes in the web structure, understanding of scrapping policies, and expanding the linguistic capabilities of the model.
The application has been brought to the attention of CRFS Labs, which has positively valued the information generated on sites of interest.